Research
Current Research Projects
Norms and Normative Expectations in Algorithmic Decision-Support Systems
This project examines the role of social norms in the use and acceptance of algorithmic decision support systems (ADSS) in the workplace. Our focus is on issues of fairness and authority that arise from using algorithms in decision-making processes, such as in personnel selection or wage determination. Given that these technologies are embedded in sociocultural contexts, we analyse the normative expectations of employees and employers. Using surveys and experiments, we explore how normative structures within organizations influence responses to and acceptance of ADSS and reactions to norm violations. By integrating insights from computer science and the social sciences, we aim to fill a gap in existing research and foster an interdisciplinary understanding of the societal impact and acceptance of AI-driven decision systems.
 Credit: Farina StockRuben Bach
Credit: Farina StockRuben Bach Credit: Katrin GlücklerDr. Daria Szafran
Credit: Katrin GlücklerDr. Daria SzafranThe Smart Survey Implementation (SSI) Project
The Smart Survey Implementation (SSI) Project, funded by EUROSTAT, seeks to advance data collection in official statistics across Europe by integrating novel digital technologies. The consortium, comprising institutions from The Netherlands (Statistics Netherlands and Utrecht University), Belgium (Statistics Belgium, Free University Brussels, and Hbits), France (Statistics France), Italy (Statistics Italy), Norway (Statistics Norway), Slovenia (Statistics Slovenia), and Germany (Statistics Germany and University of Mannheim), aims to enhance survey methodologies significantly.
Central to the SSI project is the development and testing of a smartphone application for real-time recording of daily activities and financial transactions, intended for use in official European statistics. The University of Mannheim plays a pivotal role, coordinating participant recruitment across countries and, in partnership with the German Federal Statistical Office (Destatis), leading data collection efforts in Germany. Our approach includes identifying adoption barriers, testing strategies to surmount these, and ultimately, contributing to the standardization and methodological advancement of smart survey methods in Europe.
By leveraging these collaborative efforts and innovative methodologies, the SSI project aspires to bring about a significant methodological shift in statistical research practices across Europe, setting a new standard for smart survey methods.
Read more about the project (in German)
 Credit: Katrin GlücklerProf. Dr. Florian Keusch
Credit: Katrin GlücklerProf. Dr. Florian Keusch Credit: Elene RakviashviliMaren Fritz
Credit: Elene RakviashviliMaren FritzMeasurement of Physical Activity in older adults through Data Donation (MPADD)
Physical activity (PA) is a key predictor of many health outcomes, especially for older adults. Usually, PA is measured through self-reports which are prone to measurement error. Using an innovative methodological approach, we propose to leverage the fact that many older adults now have smartphones that track PA. Individuals can share these passively collected PA data in a privacy-preserving way through a data donation tool with researchers. We intend to investigate determinants of consent and selection bias in PA data donation among 2,000 individuals aged 50 and older in the Netherlands, to assess the quality of the donated PA data, and to evaluate how multi-source PA data can predict health outcomes.
MPAAD Presentation at NIMLASCredit: Katrin GlücklerProf. Dr. Florian Keusch Bella Struminskaya
Bella StruminskayaKODAQS – The Competence Center for Data Quality in the Social Sciences
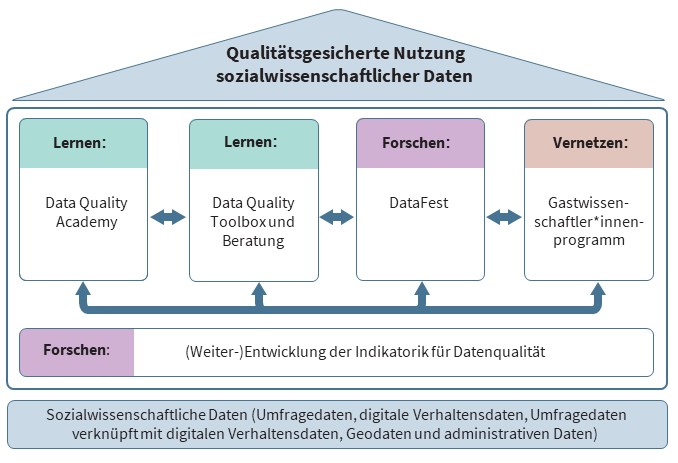
The Competence Center for Data Quality in the Social Sciences (KODAQS) aims to support and communicate the quality-assured use of social science data as a place of learning, research and networking. In addition to the traditional survey or self-report data that is still predominantly used, digital behavioral data and links between these and other data (e.g. geodata) are also included. KODAQs are intended to sensitize researchers to data quality and train them in its determination. Offers will be created that allow the use, processing, analysis and linking of social science data in a transparent and replicable manner.
The planned offerings include (1) the Data Quality Academy, which uses digital and hybrid learning opportunities to teach researchers how to handle social science data in a quality-assured manner, (2) the Data Quality Toolbox, which offers analysis codes for calculating key quality indicators with accompanying learning and consulting opportunities, (3) the DataFests, in which what has been learned is applied to one's own research in the form of hackathons, and (4) guest stays at KODAQS, in which – in cooperation with KODAQS employees – one's own research questions are examined with a view to data quality. In addition, KODAQS works with national and international experts to further develop data quality indicators.Credit: Katrin GlücklerProf. Dr. Florian Keusch Credit: Fiona DraxlerDr. Fiona Draxler
Credit: Fiona DraxlerDr. Fiona Draxler Credit: Daniela HauptProf. Dr. Frauke Kreuter
Credit: Daniela HauptProf. Dr. Frauke Kreuter Credit: Alexander MünchLaura Young
Credit: Alexander MünchLaura Young Credit: F. BemmannDr. Florian Bemmann
Credit: F. BemmannDr. Florian BemmannUtilizing the Potentials of Twin Studies to Improve Our Understanding of Satisficing Response Behaviour in Surveys
When answering survey questions, respondents may engage in satisficing response behaviour. Satisficing means not properly progressing through all steps of the cognitive response process. The proposed project extends the existing satisficing theory to include stable and dynamic characteristics of the respondent, situation, instrument, and culture and context of a survey. To disentangle the interactions in the relationship between these factors and response behaviour, the project utilizes the potentials of different international longitudinal twin studies. Building on the theoretical contributions and empirical findings of the project, solutions to improve survey questions are developed in order to mitigate satisficing.
Credit: Katrin GlücklerProf. Dr. Florian Keusch Credit: Tobias GummerTobias Gummer
Credit: Tobias GummerTobias Gummer Credit: Christof WolfProf. Dr. Christof WolfSophia Piesch, M.Sc.
Credit: Christof WolfProf. Dr. Christof WolfSophia Piesch, M.Sc.Prediction-based Adaptive Designs for Panel Surveys
Despite its promising potential to reduce attrition and biases, the use of adaptive survey designs in panel studies is lacking in both areas that are needed for its functioning: (1) In predicting nonresponse and thus creating appropriate strata as well as (2) in the treatments that are administered in practice. This project will pair the implementation and testing of innovative prediction methodology from the field of machine learning with innovative treatments that can be assigned to likely nonrespondents. Prediction models will be trained and evaluated in a longitudinal framework that is tailored to identifying panelists at risk of nonparticipation in a given (new) panel wave. The predicted risk scores of the most accurate model allow us to test the effectiveness of different treatments. Specifically, this project will investigate the usage of innovative treatments in adaptive survey designs that aim to increase survey enjoyment compared to the more common differential incentives approach. Testing these strategies on a common ground will add to previous research on adaptive designs, which has been inconclusive about which approach works best for stimulating respondents participation and engagement. Furthermore, the treatments will not only be compared and evaluated with respect to their effects on participation, but also by being mindful about other, potential unintended, consequences on data quality in the long run. In addition, the transferability of the developed methodology to other panel studies will be investigated.
The project at MZES (Mannheim Center for European Social Research)
 Credit: John James CollinsJohn CollinsBernd Weiß
Credit: John James CollinsJohn CollinsBernd WeißPublications
- Kern, Christoph ; Weiß, Bernd ; Kolb, Jan-Philipp (2021) Predicting nonresponse in future waves of a probability-based mixed-mode panel with machine learning. Journal of Survey Statistics and Methodology.
- Kern, Christoph ; Weiß, Bernd ; Kolb, Jan-Philipp (2019) A longitudinal framework for predicting nonresponse in panel surveys.
- Kolb, Jan-Philipp ; Weiß, Bernd ; Kern, Christoph Using predictive modelling to identify panel nonresponse
Understanding, Measuring, and Alleviating Inequalities in Digital Technology Use
Digital technologies, such as smartphones and tablets, are increasingly integrated into people's everyday lives. Social scientists have also started to use these technologies for data collection, such as through apps and sensors embedded in smartphones and wearable devices. Despite the increasing device penetration in the general population, inequalities in the access to and use of digital technologies persist, reflecting existing social inequalities. Digital exclusion additionally becomes a methodological issue if the digitally disadvantaged population subgroups are not well represented in social studies.
The project investigates digital inequalities in Europe and the United States by focusing on three aims: 1) studying the correlates and mechanisms of digital technology acceptance, 2) improving the measurement of digital skills and technology use, and 3) identifying effective interventions to reduce inequalities in digital technology use. Credit: Paul TaitAlexander Wenz
Credit: Paul TaitAlexander WenzPublications
- Keusch, F., Wenz, A., & Conrad, F. (2022). Do you have your smartphone with you? Behavioral barriers for measuring everyday activities with smartphone sensors. Computers in Human Behavior, 127, 107054. https://doi.org/10.1016/j.chb.2021.107054
Filter Bubbles, Alternative News and Political Polarization
Many fear that selective exposure on social media and algorithmically personalized news diets promote the creation of so-called filter bubbles and echo chambers with serious consequences for democratic societies and the functioning of political institutions and processes. In addition, researchers suspect that alternative media platforms increasingly disseminate factually dubious content. However, only few empirical studies have tackled these questions with data that are not biased due to incomplete and inaccurate self-reports. These studies, relying on detailed records of individuals' online activities, have contested some of the concerns mentioned above: Instead of, for example, fostering selective and polarized news exposure, social media and news aggregators seem to increase individuals' amount of news consumed and the number of news outlets visited. However, so far, there are hardly any findings available for Germany.
Against this background, I will study whether social media and search engines result in the creation of homogeneous news diets, filter bubbles and echo chambers. Moreover, I will investigate how much citizens are exposed to alternative media and factually dubious content, how such content is disseminated and who is most likely to consume it. Finally, I will analyze the consequences of homogeneous news use and alternative media for citizens' trust in democracy, political institutions and the media.
I will study these questions using detailed records of individuals' online activities: Web-browsing data for about 2,000 German internet users will be collected during the months leading up to and covering the next German federal election in 2021. In addition, I will run a short survey among the same users to collect information about their socio-demographic characteristics and their political preferences and attitudes.
Findings from this project will be highly relevant for both public and academic debates on selective exposure facilitated through social media and algorithmically personalized news diets. In addition, understanding the content of factually dubious content as well as who consumes factually dubious content through which channels will help to fight the spread of so-called “fake news”.
Credit: Farina StockRuben Bach Credit: Katrin GlücklerJoão Areal
Credit: Katrin GlücklerJoão ArealPublications
- Müller, P. and Bach, R. L. (2021). Populist alternative news use and its role for elections: Web-tracking and survey evidence from two campaign periods. New Media & Society, 1–21.
- Bach, Ruben L. ; Kern, Christoph ; Bonnay, Denis ; Kalaora, Luc (2022) Understanding political news media consumption with digital trace data and natural language processing. Open Access Journal of the Royal Statistical Society. Series A, Statistics in Society Oxford tba tba 1–24 [Zeitschriftenartikel]
CAIUS: Consequences of AI for Urban Societies
AI systems help to efficiently allocate scarce public resources and are at the core of many smart city activities. Yet, the same systems may also result in unintended societal consequences, particularly by reinforcing social inequalities. CAIUS will identify and analyze such consequences. Using agent-based models (ABM), the effects of AI-based decisions on societal macro variables of social inequality such as income disparity will be analyzed. The data input for these ABMs consists of both Open Government Data and own surveys. The goal is to train AI systems to account for their social consequences within specific fairness constraints; this synthesis of ABM and fair reinforcement learning lays the groundworks for what we call “impact-aware AI” in urban contexts. With CAIUS, two smart city applications planned by partners in the Rhine-Neckar Metropolitan Region will be accompanied: dynamic pricing of parking space and traffic law enforcement via Internet-of-Things sensors. The results will contribute to research of human-AI interaction and will be condensed into general guidelines for decision-makers regarding the ethical implementation of AI-based decision-making systems in urban contexts.
The project at MZESCredit: Farina StockRuben Bach Credit: Katrin GlücklerFrederic Gerdon
Credit: Katrin GlücklerFrederic GerdonPublications
- Kappenberger, J., Stuckenschmidt, H., and Gerdon, F. (2025). Pricing parking for fairness – A simulation study based on an empirically calibrated model of parking behavior. Transportation Research Part A: Policy and Practice, 193, Article 104389. https://doi.org/10.1016/j.tra.2025.104389
- Kern, C., Kappenberger, J., Gerdon, F., Strasser Ceballos, C., Szafran, D., Rupp, F., and Bach, R. (2025). A simulation framework for studying the social impacts of algorithm-based refugee matching. Proceedings of Fourth European Workshop on Algorithmic Fairness, in Proceedings of Machine Learning Research 294, 487–449. https://proceedings.mlr.press/v294/kern25a.html
- Gerdon, F., Bach, R. L., Kern, C. and Kreuter, F. (2022). Social impacts of algorithmic decision-making: A research agenda for the social sciences. Big Data & Society, 9(1), 1–13. https://doi.org/10.1177/20539517221089305
- Gerdon, F., Theil, C. K., Kern, C., Bach, R. L., Kreuter, F., Stuckenschmidt, H., and Eckert, K. (2020). Exploring impacts of artificial intelligence on urban societies with social simulations. 40. Kongress der Deutschen Gesellschaft für Soziologie, Online.
- Kern, C., Gerdon, F., Bach, R. L., Keusch, F., and Kreuter, F. (2022). Humans versus machines: Who is perceived to decide fairer? Experimental evidence on attitudes toward automated decision-making. Patterns, 3(10), 100591. https://doi.org/10.1016/j.patter.2022.100591
- Kuppler, M., Kern, C., Bach, R. L., and Kreuter, F. (2022). From fair predictions to just decisions? Conceptualizing algorithmic fairness and distributive justice in the context of data-driven decision-making. Frontiers in Sociology, 7, 1–18
- Kuppler, M., Kern, C., Bach, R. L., and Kreuter, F. (2021). Distributive justice and fairness metrics in automated decision-making: How much overlap is there? Ithaca, NY: Cornell University.
BERD – Business and Economics Data Center (BERD@BW)
The aim of BERD@BW is to establish a competence center for data availability, data exchange and data analysis. The project also includes the development of training and further education. These courses will use concrete case studies to teach skills that researchers need for data-based work. Thanks to its extensive experience with the International Program in Survey and Data Science and the Coleridge Initiative in the USA, the chair can provide excellent support in course development.
Project-Team
 Credit: Markus HerklotzMarkus Herklotz
Credit: Markus HerklotzMarkus HerklotzFairADM: Fairness and discrimination in automated decision-making processes
The project „Fairness in Automated Decision-Making (Fair ADM)“ by Prof. Dr. Frauke Kreuter, Dr. Ruben Bach and Dr. Christoph Kern from the Chair of Statistics and Social Science Methodology, deals with discrimination and fairness of algorithm-based decision-making processes (Automated Decision-Making, ADM) in the German public sector. „While ADM systems optimize bureaucratic procedures through automation, their use also raises new social and ethical questions,“ says Prof. Dr. Frauke Kreuter. It is feared that ADM could increase existing social discrimination. For example, ADM systems are already being used in the U.S. to assess the risk of recidivism of defendants in the context of legal proceedings. A particularly sensitive field of application of ADM in the European context is the assessment of job seekers' chances on the labour market, e.g. for the allocation of training resources, which has recently been proposed by the Austrian Public Employment Service (AMS). There is a risk that sensitive characteristics such as gender, age or marital status are brought into the algorithmic decision-making process and thus influence the distribution of resources. In order to shed more light on this and to empirically investigate methods to correct unfair algorithms, the project develops and evaluates an ADM based on administrative labour market data. This research is supported with 171.000 Euro.
Read more about the projects in the University's press release (in German)
Project team
 Credit: Daniela HauptChristoph KernCredit: Farina StockRuben Bach
Credit: Daniela HauptChristoph KernCredit: Farina StockRuben BachPublications
- Kuppler, M., Kern, C., Bach, R. L. and Kreuter, F. (2022). From fair predictions to just decisions? Conceptualizing algorithmic fairness and distributive justice in the context of data-driven decision-making. Frontiers in Sociology, 7, 1–18
- Kuppler, M., Kern, C., Bach, R. L. and Kreuter, F. (2021). Distributive justice and fairness metrics in automated decision-making: How much overlap is there? Ithaca, NY: Cornell University.
- Kern, C., Bach, R. L., Mautner, H. and Kreuter, F. (2021). Fairness in algorithmic profiling: A German case study. Ithaca, NY: Cornell University.
CLIKK: Chinese Language Education with LLMs and a Focus on Intercultural Communication Competences
Mandarin is considered a linguistically and structurally distant foreign language in German-speaking regions and is highly context-dependent, making the development of intercultural competence particularly important for learners. Intercultural interactions also carry a high risk of violating social norms, which can lead to negative socio-emotional consequences. However, these consequences are difficult to recognize, understand, and train in real-life scenarios. A lack of intercultural competence and the resulting norm-deviating linguistic behavior can hinder interaction, learning, and motivation.
The goal of CLIKK is to foster intercultural competence in ChaF (Chinese as a foreign language) education by utilizing Large Language Models (LLMs) and Social Interactive Agents (SIAs) as virtual social agents. These agents aim to help Chinese learners develop intercultural communicative competence (ICC) by creating realistic and interactive learning scenarios. To achieve this, the project investigates how LLMs need to be adapted to function as SIAs that can simulate specific intercultural communication situations in a realistic and dynamic way. For successful development, the interactions will be analyzed using conversation analysis to describe the conversations, identify specific learning-related episodes, and detect conversational disruptions. Additionally, we will investigate the emotional experiences of the learners and discuss pedagogical-didactic with ChaF teachers. Based on these findings, the LLM models will be refined, and guidelines for using SIAs to promote ICC in ChaF teaching and learning will be developed.Project team
Finished Projects
Mobility Survey Cluster Sinsheim
The CO2 reduction of motorised individual transport is the greatest policy lever for climate protection in domestic tourism in the Rhine-Neckar metropolitan region. As a basis for the development of effective measures to promote sustainable mobility, a mobility survey will be carried out in collaboration with the Metropolregion Rhein-Neckar GmbH. The survey will be conducted in the city of Sinsheim, Baden-Württemberg among visitors of three regional points of interest: Technik Museum Sinsheim, Thermen & Badewelt Sinsheim,and TSG Hoffenheim. This project investigates the status quo of visitors’ mobility patterns, and their satisfaction with the current options to travel to and from the points of interest. In addition, future needs for sustainable mobility are collected.
Credit: Katrin GlücklerProf. Dr. Florian Keusch Credit: Marlene BauerMarlene Bauer
Credit: Marlene BauerMarlene BauerInternational Program in Survey Practice and Data Science
The University of Mannheim will develop in cooperation with the University of Maryland an international online continuing education program in the area of data collection and data analysis. Development will take place in cooperation with several partners in Germany with expertise in this area: the Leibniz-Institut für Sozialwissenschaften (GESIS) and the Institut für Arbeitsmarkt- und Berufsforschung (IAB). GESIS has been active in the German survey arena for a long time, with research, education and consulting services. Particularly noticeable are its services as part of the German Micro Census and its coordination of the European Social Survey, as well as the administration of the PIAAC-Study for the OECD in Germany. The Institut für Arbeitsmarkt- und Berufsforschung (IAB) regularly conducts its own surveys such as the IAB-Betriebspanel or the Panel Arbeitsmarkt und Soziale Sicherung. Hosting the research data center, Forschungsdatenzentrum der Bundesagentur für Arbeit (FDZ), and within the German Record Linkage Center, the IAB is an international leader in data linkage as well as empirical questions with regard to data privacy protection. In the second phase of the project, it is planned to expand the cooperation to include the Institut für Statistik of the Ludwig-Maximilians-Universität München.
The planned continuing education project will employ internet-based learning methods that will provide continuous asynchronous access to educational material as well as enable an interactive exchange between lecturers and students. In combination with several on-site lectures and seminars, on-site activities, topical chats, online forums, and video-based material will enable participants in the program to build an international professional network.
Within this program of continuing eductation, a master's degree can be earned within one year upon full-time attendance and within a respectively longer time period upon part-time attendance. The program will start with an introductory on-site workshop in which students and lecturers will get to know each other and in which the online infrastructure will be explained. The core of the program consists of four base modules, followed by speciality lectures and seminars. Throughout the course of the program participants must attend a total of two workshops on-site at the location of any of the participating institutions. To reduce typical barriers to professional training, childcare will be offered at all on-site activities. In so doing, the program will make use of the existing infrastructure at the Universität Mannheim. At each of the collaborating institutions there will be a program manager responsible for coordinating the sites and who will serve as the direct contact person for the students. The effectiveness of the program will be evaluated by analyzing the reactions of the participants to the material provided, learning outcomes in terms of improved qualifications, use of learned material in their respective jobs, effects upon job performance, and estimates of rate of return. A core feature of the first development phase is a series of small randomized experiments in which different online learning modules will be tested empirically. Based on the results of the first phase, in the second phase the program will be expanded geographically and thematically, and the foundation laid for a sustainable infrastructure.If you are interested in detailed information about the curriculum, admission criteria and enrollment, please check the program's website.
Publications
- Haensch, A.-C., Herklotz, M., Keusch, F., & Kreuter, F. (2021). The International Program in Survey and Data Science (IPSDS): A modern study program for working professionals. Statistical Journal of the IAOS, 37, 921–933. https://doi.org/10.3233/SJI-210833
- Keusch, F. & Kreuter, F. (2020). Zukunft der Aus- und Weiterbildung in der Markt- und Sozialforschung. In B. Keller (eds.), Marktforschung für die Smart Data World : Chancen, Herausforderungen und Grenzen (S. 3–25). Wiesbaden: Springer Gabler. https://doi.org/10.1007/978-3-658-28664-4_1
- Samoilova, E., Wolbring, T. & Keusch, F. (2020). Datenqualität umfragebasierter Workload-Messungen: Eine Mixed-Methods-Studie auf Grundlage von Learning Analytics und kognitiven Interviews. In C. Engel (eds.), Studentischer Workload (S. 205–229). Wiesbaden: Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-28931-7_8
- Kreuter, F., Keusch, F., Samoilova, E. & Frößinger, K. (2018). International program in survey and data science. In C. König (eds.), Big Data : Chancen, Risiken, Entwicklungstendenzen (S. 27–41). Wiesbaden: Springer VS. https://doi.org/10.1007/978-3-658-20083-1_4
- Samoilova, E., Keusch, F. & Kreuter, F. (2018). Integrating survey and learning analytics data for a better understanding of engagement in MOOCs. In H. Jiao (eds.), Data analytics and psychometrics : informing assessment practices (S. 247–261). Charlotte, NC: Information Age Publishing.
- Samoilova, E., Keusch, F. & Wolbring, T. (2017). Learning analytics and survey data integration in workload research. Zeitschrift für Hochschulentwicklung : ZFHE, 12(1), 65–78. https://doi.org/10.3217/zfhe-12-01/04
Integration research 2.0 – Harnessing the power of new data sources to advance knowledge on behavior and attitudes of migrants and natives
Research question/
goal: For decades, social scientists have mainly relied on self-reported data from surveys to study integration efforts of refugees and migrants as well as natives’ attitudes on immigrants and immigration policies. Together with administrative records (e.g., from asylum registration centers, welfare agencies, and employment offices), these data are an important resource for decision-makers on every federal level to manage integration tasks and design integration policies. However, the collection of these data can be slow and expensive (e.g., with regard to conducting large-scale surveys or obtaining access to administrative data), and they are susceptible to social desirable reporting (e.g., when measuring sensitive attitudes and behaviors through self-reports). As a consequence, the resulting findings are often only available after an extended period of time and potentially biased.
With the financial support of the Fritz Thyssen Stiftung, this project aims at overcoming these issues. In particular, we draw on our past work and propose to study three new forms of data and novel approaches to data collection that promise faster, more frequent, and potentially also more accurate information for social science research in general and studies on immigration and integration in particular: (1) passively collected data from smartphone sensors and apps, (2) aggregated Internet search queries, and (3) responses obtained from voting advice applications like the German Wahlomat. Each of these approaches has its own limitations, but they could make significant contributions through complementing traditional data collection and overcoming some of its shortcomings.
The results from this project will inform methodological best practices in using these new data sources as supplements to traditional ones, especially when examining integration-related topics. The findings will thus help advance the field of integration research and the social sciences in general by adapting new technological possibilities that will enable researchers to answer existing research questions better and to investigate completely new issues.
Publications
- Lorenz, R., Beck, J., Horneber, S., Keusch, F., & Antoun, C. (2022). Google Trends as a tool for public opinion research: An illustration of the perceived threats of immigration. In Pötzschke, S. & Rinken, S. (Eds.) Migration Research in a Digitalized World, 193–206. Cham: Springer. https://doi.org/10.1007/978-3-031-01319-5_10
IAB-SMART: Collecting Data for Labor Market Research Through a Smartphone App
Smartphones are multifunctional tools, which can be used for personal communication, planning, entertainment, information search, and many other things in our daily lives. Many people cannot imagine a life without their smartphone, and they carry them around with them all the time. The omnipresence of smartphones makes these devices interesting for researchers who want to collect data to measure human behavior through sensors built in on a smartphone.
Together with the Institute for Employment Research (IAB) we developed the IAB-SMART app to evaluate the opportunities and challenges when using smartphones for data collection in social research, more specifically on labor market research. The IAB-SMART app passively collects mobile data, such as geolocation of users, activities, social interactions, and online behavior, and launches in-app surveys. In addition, we are able to combine these data (given the user’s consents) with survey data from a longstanding panel survey (PASS) and administrative data from the Institute for Employment Research (IAB) containing the employment history of users.
The passive measures allow researchers to take a wider perspective on labor market related behavior such as home office productivity and job search strategies. Furthermore, the combination of sensor, survey and administrative data will help us to understand how (un)employment affects daily life. In addition to these substantial questions, this project helps us answer methodological research questions on the quality of the data collected through this method.Project Team
Georg-Christoph HaasMark TrappmannSebastian BährPublications
- Trappmann, M., Haas, G.-C., Malich, S., Keusch, F., Schwarz, S., Bähr, S., & Kreuter, F. (2022). Augmenting survey data with other data types: Is there a threat to panel retention? Journal of Survey Statistics and Methodology. Published online before print June 28, 2022. https://doi.org/10.1093/jssam/smac023
- Keusch, F., Bähr, S., Haas, G.-C., Kreuter, F., Trappmann, M., & Eckman, S. (2022). Nonparticipation in smartphone data collection using research apps. Journal of the Royal Statistical Society. Series A. Published online before print April 12, 2022. https://doi.org.10.1111/rssa.12827
- Bähr, S., Haas, G.-C., Keusch, F., Kreuter, F., & Trappmann, M. (2022). Missing data and other measurement quality issues in mobile geolocation sensor data. Social Science Computer Review, 40, 212–235. https://doi.org10.1177/0894439320944118
- Malich, S., Keusch, F., Bähr, S., Haas, G.-C., Kreuter, F., & Trappmann, M. (2021). Mobile Datenerhebung in einem Panel. Die IAB-SMART Studie. In Wolbring, T., et al. (Eds.) Sozialwissenschaftliche Datenerhebung im digitalen Zeitalter, 45–69. Wiesbaden: Springer. https://doi.org/10.1007/978-3-658-34396-5_2
- Haas, G.-C., Kreuter, F., Keusch, F., Trappmann, M., & Bähr, S. (2021). Effects of incentives in smartphone data collection. In Hill, C.A., et al. (Eds.) Big Data Meets Survey Science: A Collection of Innovative Methods, 387–414. Hoboken, NJ: Wiley. https://doi.org/10.1002/9781118976357.ch13
- Haas, G., Trappmann, M., Keusch, F., Bähr, S., & Kreuter, F. (2020). Using geofences to collect survey data: Lessons learned from the IAB-SMART study. Survey Methods: Insights from the Field. https://doi.org/10.13094/SMIF-2020-00023
- Keusch, F., Bähr, S., Haas, G.-C., Kreuter, F., & Trappmann, M. (2020). Coverage error in data collection combining mobile surveys with passive measurement using apps: Data from a German national survey. Sociological Methods & Research. Published online before print April 7, 2020. https://doi.org/10.1177/0049124120914924
- Kreuter, F., Haas, G.-C., Keusch, F., Bähr, S., & Trappmann, M. (2020). Collecting survey and smartphone sensor data with an app: Opportunities and challenges around privacy and informed consent. Social Science Computer Review, 38, 533–549. https://doi.org/10.1177/0894439318816389
- Bähr, S., Haas, G.-C., Keusch, F., Kreuter, F. & Trappmann, M. (2018). IAB-SMART-Studie: Mit dem Smartphone den Arbeitsmarkt erforschen. IAB-Forum: Das neue Onlinemagazin des Instituts für Arbeitsmarkt- und Berufsforschung. https://www.iab-forum.de/iab-smart-studie-mit-dem-smartphone-den-arbeitsmarkt-erforschen/
Supplementing and substituting survey data with big data
For many years, surveys were the standard tool to measure attitudes and behavior for social science research. In recent years, however, researchers have shifted their focus to new sources of data, especially in the online world. For instance, researchers have analyzed the potentials of replacing or supplementing survey data with data from Twitter, smart devices (e.g., smartphones or fitness tracker) and data from other places where people leave digital traces. In this project, we explore the feasibility of using behavioral records of individuals’ online activities to study political attitudes and behavior. Specifically, we explore the potentials of online behavioral data to substitute traditional survey data by inferring attitudes and behavior from the online data. In addition, we analyze how complete such data are as users may switch off data collection during certain activities they do not want recorded. Moreover, we study how (social) media use shapes attitudes and behavior in the offline world. This project is done in collaboration with Ashley Amaya (RTI International).
Project Team
Credit: Farina StockRuben BachAshley AmayaJan HechtJonathan HeinemannPublications
- Bach, R. L., Kern, C., Bonnay, D. & Kalaora, L. (2022). Understanding political news media consumption with digital trace data and natural language processing. Journal of the Royal Statistical Society. Series A, Statistics in Society, 1–24. https://doi.org/10.1111/rssa.12846
- Keusch, F., Bach, R., & Cernat, A. (2022). Reactivity in measuring sensitive online behavior. Internet Research. Published online before print August 9, 2022. https://doi.org/10.1108/INTR-01-2021-0053
- Cernat, A. & Keusch, F. (2022). Do surveys change behaviour? Insights from digital trace data. International Journal of Social Research Methodology, 25, 79–90. https://doi.org/10.1080/13645579.2020.1853878
- Amaya, A., Bach, R.L., Keusch, F., & Kreuter, F. (2021). New data sources in social science research: Things to know before working with Reddit data. Social Science Computer Review, 39, 943–960. https://doi.org/10.1177/0894439319893305
- Bach, R.L., Kern, C., Amaya, A., Keusch, F., Kreuter, F., Hecht, J., & Heinemann, J. (2021). Predicting voting behavior using digital trace data. Social Science Computer Review, 39, 862–883. https://doi.org/10.1177/0894439319882896
- Bach, R. L. und Wenz, A. (2020). Studying health-related internet and mobile device use using web logs and smartphone records. PLOS ONE, 15, e0234663. https://doi.org/10.1371/journal.pone.0234663
Reddit data as a new tool and source for social research
The use of non-traditional data (i.e., data collected from non-probability sample surveys, passive data, or Big Data) to supplement or replace survey data is growing. However, these data are not without weaknesses; they suffer from their own sources of error, access challenges, and confidentiality concerns. This project uses survey data collected on and posts scraped from Reddit.com to answer three research questions: 1) Can social media data be used to accurately assess social attitudes? 2) What are the sources of error in social media data? 3) What variability in the conclusions drawn from these data is introduced by the researcher’s choice in analytic methods? In addition to the research questions, this project also offers some descriptions of the data and access to it so future Reddit data users can further refine their budgets, timelines, and expectations.
Project Team
Credit: Farina StockRuben BachAshley Amaya Credit: Jula JacobVlad Achimescu
Credit: Jula JacobVlad AchimescuPublications
- Achimescu, V. & Chachev, P. D. (2021). Raising the flag: Monitoring user perceived disinformation on reddit. Information, 12, 4. https://doi.org/10.3390/info12010004
- Amaya, A., Bach, R.L., Keusch, F., & Kreuter, F. (2021). New data sources in social science research: Things to know before working with Reddit data. Social Science Computer Review, 39, 943–960. https://doi.org/10.1177/0894439319893305
- Amaya, A., Bach, R., Keusch, F., & Kreuter, F. (2021). Measuring attitude strength in social media data. In Hill, C.A., et al. (Eds.) Big Data Meets Survey Science: A Collection of Innovative Methods, 163–192. Hoboken, NJ: Wiley. https://doi.org/10.1002/9781118976357.ch5
Modernizing Migration Measures: Combining Survey and Tracking Data Collection Among Asylum-Seeking Refugees
Collecting information about refugees is necessary to guide policy makers in creating sustainable integration concepts and to increase the scientific understanding of migration and integration processes in general. However, interviewing refugees in immigration reception centres and following them in a longitudinal study can be difficult. In this project, we assess the feasibility of data collection via smartphones among refugees in Germany. While using smartphones to collect mobile web survey data has become increasingly popular over the last couple of years, combining these data with automatic tracking of online behaviour and geolocation of the smartphone is a novel approach that requires thorough empirical testing. The project provides both methodological insight into how to utilize smartphone data collection (combining survey and tracking data) and much-needed scientifically based knowledge on the needs, aspirations, and life circumstances of refugees in Germany.
The project at MZES (Mannheim Center for European Social Research)
Project Team
 Credit: Jula JacobMariel Leonard
Credit: Jula JacobMariel Leonard Credit: Alexander MünchDr. Christoph SajonsSusan Steiner
Credit: Alexander MünchDr. Christoph SajonsSusan SteinerPublications
- Keusch, F., Leonard, M.M., Sajons, C., & Steiner, S. (2021). Using smartphone technology for research on refugees – Evidence from Germany. Sociological Methods & Research, 50, 1863-1894. https://doi.org/10.1177/0049124119852377
New Methods for Job and Occupation Classification
Currently, most surveys ask for occupation with open-ended questions. The verbatim responses are coded afterwards into a classification with hundreds of categories and thousands of jobs, which is an error-prone, time-consuming and costly task. When textual answers have a low level of detail, exact coding may be impossible. The project investigates how to improve this process by asking response-dependent questions during the interview. Candidate job categories are predicted with a machine learning algorithm and the most relevant categories are provided to the interviewer. Using this job list, the interviewer can ask for more detailed information about the job. The proposed method is tested in a telephone survey conducted by the Institute for Employment Research (IAB). Administrative data are used to assess the relative quality resulting from traditional coding and interview coding. This project is done in cooperation with Arne Bethmann (IAB, University of Mannheim), Manfred Antoni (IAB), Markus Zielonka (LIfBi), Daniel Bela (LIfBi), and Knut Wenzig (DIW).
Trust when Sharing Data Online
Decisions about confidentiality protection measures to be applied to data dissemination must be informed by evidence about the utility associated with the quality of the data and the willingness to trade utility against the estimated risk. Doing so requires measurement of data utility, risk, and the willingness of individuals to trade risk for utility. From the theoretical literature on measuring privacy (Nissenbaum 2011) and trust (Bauer and Freitag 2018), perceptions of trust and privacy are context dependent. There are three dimensions that are particular important: (1) to whom the data is provided, (2) what is done with the data (i.e., whether there are benefits for the one receiving the data vs. benefits for the one providing the data), and (3) what kind of data is shared (i.e., the sensitivity of the data). Some data are inherently sensitive because they touch taboo topics (e.g., information on income, sexual behavior, etc.), other data is only sensitive if it reveals specific information about illegal (e.g., illicit drug use) or counter-normative behaviors and attitudes (Tourangeau and Yan 2007). In this project, we measure utility, risk, and tradeoffs in the context of privacy and data sharing in several cross-sectional surveys. The data landscape has dramatically changed in May of 2018 when GDPR came into effect, and with it the control people have about their data, and the risks companies face when violating GDPR. Thus, we also collect longitudinal data on the awareness about the GDPR regulations in Germany, and in an experimental setting, we measure the influence of GDPR information on trust in various data collecting organizations.
Publications
- Bauer, P.C., Gerdon, F., Keusch, F., Kreuter, F., & Vannette, D. (2021). Did the GDPR increase trust in data collectors? Evidence from observational and experimental data. Information, Communication and Society. Published online before print May 23, 2021. https://doi.org/10.1080/1369118X.2021.1927138
- Bauer, P. C., Keusch, F. & Kreuter, F. (2019). Trust and cooperative behavior: Evidence from the realm of data-sharing. PLOS ONE, 14(8), e0220115. https://doi.org/10.1371/journal.pone.0220115
Concerns and Willingness to Use Smartphones for Data Collection
Smartphone use is on the rise worldwide, and researchers are exploring novel ways to leverage the capabilities of smartphones for data collection. Mobile surveys, i.e., surveys that are filled out on a smartphone web browser or through an app, are already extensively studied. Research on the use of other features of smartphones that allow researchers to automatically measure an even broader set of characteristics and behaviors of users that go far beyond the collection of mere self-reports is still in its infancy. For example, smartphone users can now be asked to take pictures of receipts to better measure expenditure, to agree to tracking of movements to create exact measures of mobility and transportation, or to automatically log app use, Internet searches, and phone calling and text messaging behavior to measure social interaction. These forms of data collection provide richer data (because it can be collected in much higher frequencies compared to self-reports) and have the potential to decrease respondent burden (because fewer survey questions need to be asked) and measurement error (because of reduction in recall errors and social desirability). However, agreeing to engage in these forms of data collection from smartphones is an additional step in the consent process, and participants might feel uncomfortable sharing specific data with researchers due to security, privacy, and confidentiality concerns. Moreover, users might have differential concerns with different types of data collection on smartphones, and thus be more willing to engage in some of these data collection tasks than in others. In addition, participants might differ in their skills of smartphone use and thus feel more or less comfortable using smartphones for research, leading to bias due to differential nonparticipation of specific subgroups. In a series of studies, we measure concerns and willingness when it comes to participation in smartphone data collection.
Bella StruminskayaMick CouperChristopher AntounPublications
- Keusch, F., Struminskaya, B., Kreuter, F. & Weichbold, M. (2020). Combining active and passive mobile data collection : A survey of concerns. In C. A. Hill (eds.), Big data meets survey science : a collection of innovative methods (S. 657–682). Hoboken, NJ: John Wiley & Sons. https://doi.org/10.1002/9781118976357.ch22
- Struminskaya, B. & Keusch, F. (2020). Editorial: From web surveys to mobile web to apps, sensors, and digital traces. Survey Methods : Insights from the Field, 2020(10/12/20), 1–7. https://doi.org/10.13094/SMIF-2020-00015
- Struminskaya, B., Lugtig, P., Keusch, F. & Höhne, J. K. (2020). Augmenting surveys with data from sensors and apps: Opportunities and challenges. Social Science Computer Review : SSCORE. https://doi.org/10.1177/0894439320979951
- Keusch, F., Struminskaya, B., Antoun, C., Couper, M. P. & Kreuter, F. (2019). Willingness to participate in passive mobile data collection. Public Opinion Quarterly : POQ, 83(S1), 210–235. https://doi.org/10.1093/poq/nfz007
Conversational Interviewing and Interviewer Variance (CIIV)
Standardized Interviewing (SI) requires survey interviewers to read questions as worded and provide only neutral or non-directive probes in response to questions from respondents. While many major surveys in the government, non-profit, and private sectors use SI in an effort to minimize the effects of interviewers on data quality, the existing literature shows that
between-interviewer variance in key survey statistics still arises despite the assignment of random subsamples to interviewers. Because this type of between-interviewer variance affects the precision of a survey estimate just like sample size, it has direct cost implications when designing a survey. Survey methodologists suspect that despite proper training in SI, interviewers may still diverge from scripts (even though they are not trained to) because additional explanation is often requested by survey respondents.Conversational Interviewing (CI) is known to handle clarification requests in a more effective manner: Interviewers are trained to read questions as worded, initially, and then say whatever is required to help respondents understand the questions. Despite literature demonstrating that CI produces noticeable decreases in the measurement error bias of survey estimates, survey researchers (and governmental agencies in particular) have been hesitant to employ it in practice, in part because of increased questionnaire administration time but also due to the fear of increased interviewer variance. The proposed research activity aims to compare the interviewer variance, bias, and mean squared error (MSE) arising in a variety of survey estimates from these two face-to-face interviewing techniques, and decompose the total interviewer variance introduced by each technique into measurement error variance and nonresponse error variance among interviewers. Doing so requires interpenetrated assignment of sampled cases to professional interviewers in addition to the presence of high-quality administrative records, and we performed an original data collection in Germany with these required features to meet our research aims.
Mannheim Exit Poll
On 14 June 2015, student researchers from the University of Mannheim conducted an exit poll of voters in the City of Mannheim mayoral election. A total of 1,575 voters in five randomly selected precincts were surveyed on a range of topics, including their voting behavior, social and political attitudes, and views on local services and issues. The data collection and analysis for this project are held in conjunction with the Department of Sociology Empirisches Forschungspraktikum I and II classes.
Media Coverage: FORUM, the magazine of the University of Mannheim (2/2015 issue, p.37)
Television station RNF election day news broadcast (Video – Mannheim Exit Poll at 1:05)
http://www.rnf.de/mediathek/video/mannheim-die-stimmung-am-tag-der-oberbuergermeister-wahl/Survey Managers
Questionnaire Development and Interviewing Team
Clara Beitz, Christina Bott, Markus Büger, Angela Buschmann, Larissa Ernst, Julius Fastnacht, Rolf Fröschle, Tabea Gering, Max Hansen, Anika Herter, Büsra Karaca, Marina König, Klara Kuhn, Anna Merz, Sandra Mingham, Sevda Mollaoglu, Daniel Parstorfer, Marina Röhrich, Tom Sauer, Erika Schuller, Daria Schulte, Hannah Soiné, Mona Wirth
Analytics Team
Eva Bengert, Felix Bölingen, Babette Bühler, Katharina Burgdorf, Angela Buschmann, Johanna Eisinger, Larissa Ernst, Rolf Fröschle, Max Hansen, Dorothea Harles, Anika Herter, Ina Holdik, Samir Khalil, Lisa Kirschbaum, Marina König, Lisa Kühn, Luisa Maigatte, Monika Matuschinski, Sandra Mingham, Nneka Mmeh, Sevda Mollaoglu, Lisa Natter, Julia Riffel, Sarah Schneider, Erika Schuller, Frederik Unruh, Annika Wagner, Mona Wirth, Clara Zimmer

{kind=link}